探索アルゴリズム
探索 アルゴリズムの学習 ノート。
配列探索アルゴリズム
- これらのアルゴリズムは主 にソート済 みまたは未 ソートの配列 での検索 に使用 される
- どのアルゴリズムを選択 するかは、データがソートされているか、データセットのサイズ、検索頻度 に依存 する
| アルゴリズム | 利点 | 欠点 | 使用場面 |
|---|---|---|---|
| 線形探索 | 実装 が簡単 、未 ソートデータに対応 | 大規模 データセットでは非効率 | 小規模 データセット |
| 二分探索 | 高効率 | データが事前 にソートされている必要 あり | 大規模 ソート済 みデータ |
| 補間探索 | 均一分布 データでは非常 に高速 | 非均一分布 データでは非効率 | 大規模 均一分布 数値配列 |
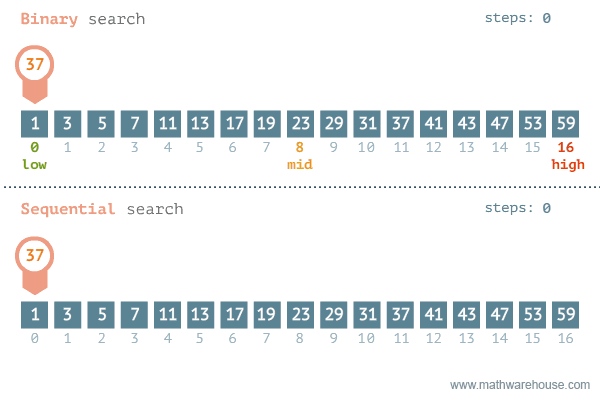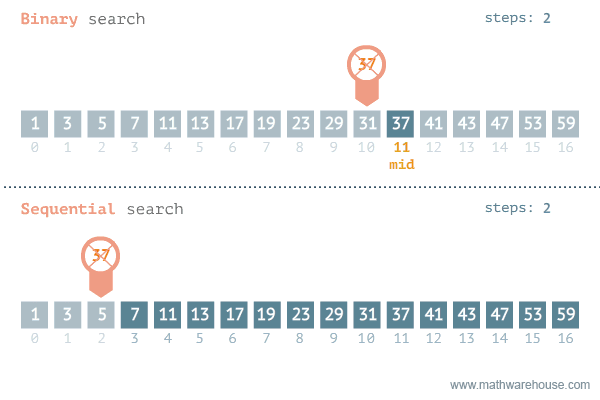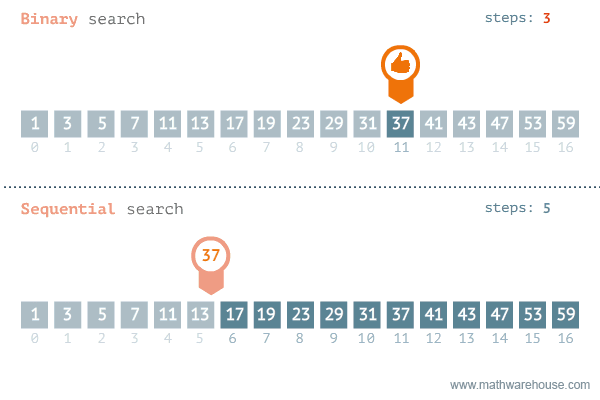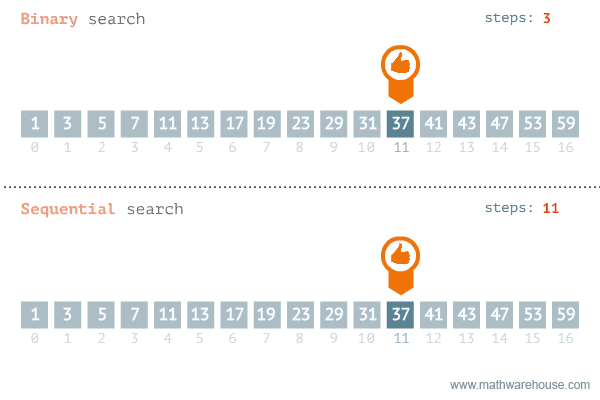
Binary Search
二分探索 - ソート済 み配列 で効率的 に目標値 を検索
- Time Complexity
- Best:
- Average:
- Worst:
- Space Complexity:
- 反復 :
- 再帰 :
Interpolation Search
補間探索 - 均一分布 データに最適化 された探索 アルゴリズム
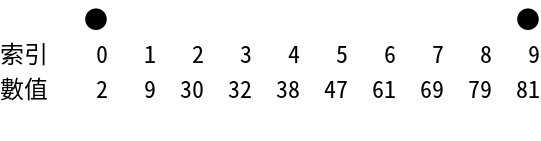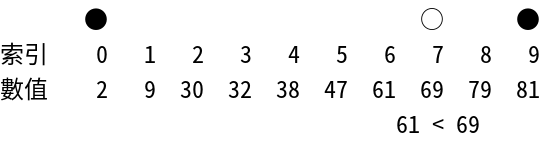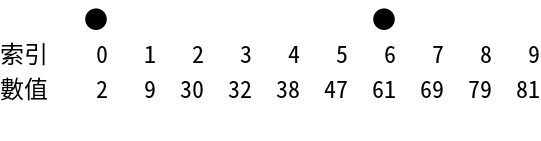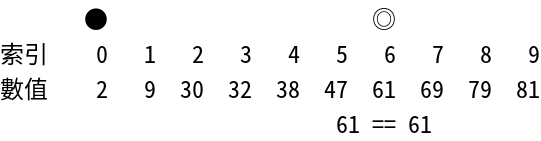
- Time Complexity
- Best:
- Average (均一分布 データ):
- Worst:
- Space Complexity:
グラフ探索アルゴリズム
- これらのアルゴリズムはグラフ構造 (ソーシャルネットワーク、地図 など)での経路 や特定 ノードの検索 に使用 される
| アルゴリズム | 利点 | 欠点 | 使用場面 |
|---|---|---|---|
| 深 さ優先探索 (DFS) | メモリ効率 が良 い | 深 い分岐 に陥 る可能性 | 迷路解決 、トポロジカルソート |
| 幅優先探索 (BFS) | 最短経路 を発見 | メモリ消費 が大 きい | 最短経路問題 |
| Dijkstra法 | 単一始点最短経路 を発見 | 負 の重 みには非対応 | ナビゲーション、ネットワークルーティング |
| A*探索 | 最良優先探索 とヒューリスティックの組 み合 わせ | ヒューリスティック関数 の選択 が効率 に影響 | 経路計画 、ゲームAI |
文字列探索アルゴリズム
- 主 にテキスト処理 、パターンマッチングに使用 される
| アルゴリズム | 利点 | 欠点 |
|---|---|---|
| KMP法 | 効率的 な文字列 マッチング | 実装 が複雑 |
| Rabin-Karp法 | 複数 パターンを同時 に検索可能 | ハッシュ関数 の選択 が効率 に影響 |
| Boyer-Moore法 | 実用上 他 の文字列 アルゴリズムより優秀 | 前処理 が複雑 |
確率的探索アルゴリズム
- これらのアルゴリズムは通常 、複雑 な最適化問題 や大規模 な探索空間 に使用 される
| アルゴリズム | 利点 | 欠点 |
|---|---|---|
| モンテカルロ木探索 (MCTS) | 大 きな状態空間 に適用可能 | 良 い結果 を得 るには多 くのシミュレーションが必要 |
| 焼 きなまし法 | 局所最適解 から脱出可能 | 大域最適解 の発見 は保証 されない |
| 遺伝的 アルゴリズム | 複雑 な最適化問題 を処理可能 | パラメータ調整 が複雑 |
特殊探索アルゴリズム
- ハッシュ探索 とブルームフィルタは大規模 データセットの高速検索 に使用 される
| アルゴリズム | 利点 | 欠点 |
|---|---|---|
| ハッシュ探索 | ハッシュテーブルで定数時間 に近 い検索 | 追加 ストレージが必要 、ハッシュ衝突 の可能性 |
| ブルームフィルタ | 空間効率 が高 い、検索 が高速 | 偽陽性 の可能性 あり、削除非対応 |