RAG
RAG (Retrieval-Augmented Generation) 検索拡張生成
核心概念 :情報検索 と大規模言語 モデルを組 み合 わせ、回答生成前 に知識 ベースから関連情報 を検索 する。
アーキテクチャフロー
- Query - ユーザーが質問 を入力
- Retrieval - ベクトルデータベースから関連文書 を検索
- Augmentation - 検索結果 と元 の質問 を結合
- Generation - LLM が拡張 されたコンテキストに基 づいて回答 を生成
メリット
- ハルシネーション(幻覚 )の削減
- 知識 を即時更新可能 (モデルの再訓練不要 )
- 回答 の出典 を追跡可能
ユースケース
- 企業 知識 ベース Q&A
- 文書検索 と要約
- カスタマーサポートボット
ベクトルデータベース実装 (Redis)
出典 :Redis University RU402 コースノート
環境設定
初回実行時
に embedding モデル all-MiniLM-L6-v2 をダウンロード
:
python -m venv redisvenv
source ./redisvenv/bin/activate
pip install sentence_transformers
pip install imgbeddingsRedis でベクトルを保存
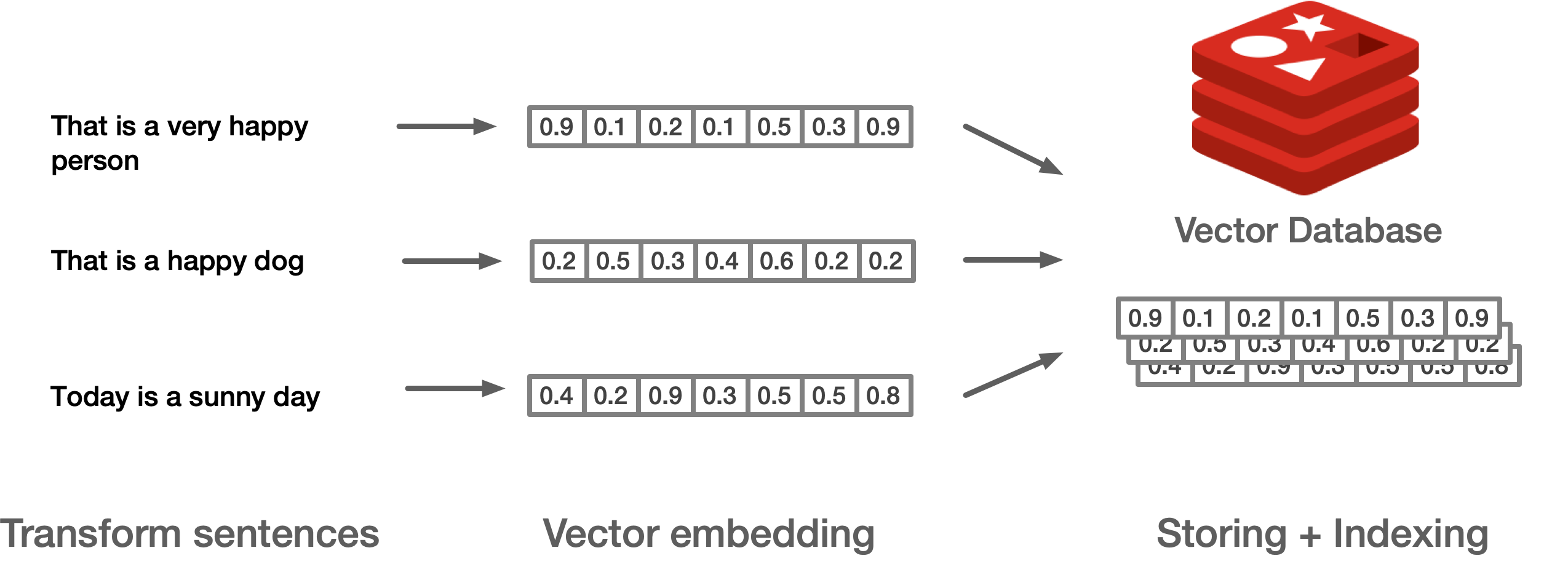
ベクトルは Redis に文字列形式 で保存 され、シリアライズ してから格納 する必要 がある:
SET vec "0.00555776,0.06124274,-0.05503812,-0.08395513,-0.09052192,-0.01091553,-0.06539601,0.01099653,-0.07732834,0.0536432"Hash と JSON データ型の使用
all-MiniLM-L6-v2embedding モデルでベクトルを計算- 最大 256 単語 のテキストを 384 次元 ベクトル空間 にマッピング
Hash 保存方式
ベクトルはバイナリ blob として Hash に保存 :
{
"content": "Understanding vector search is easy, but understanding all the mathematics behind a vector is not!",
"genre": "technical",
"embedding": "..."
}FT.CREATE でインデックス作成
FT.CREATE doc_idx ON HASH PREFIX 1 doc: SCHEMA content AS content TEXT genre AS genre TAG embedding VECTOR HNSW 6 TYPE FLOAT32 DIM 384 DISTANCE_METRIC COSINE設定 説明 :
- DIM 384 - ベクトル次元 (embedding モデルで決定 )
- HNSW - インデックス方法
- FLOAT32 - ベクトルデータ型
- COSINE - 距離計算方式
JSON 保存方式
FT.CREATE doc_idx ON JSON PREFIX 2 doc: SCHEMA $.content as content TEXT $.genre AS genre TAG $.embedding VECTOR HNSW 6 TYPE FLOAT32 DIM 384 DISTANCE_METRIC COSINEインデックス方法の比較
| 方法 | 説明 | 適用 シーン |
|---|---|---|
| FLAT | 全 てのベクトルを一 つずつ比較 、正確 だが遅 い | 小規模 データセット |
| HNSW | 確率 アルゴリズムを使用 、精度 を犠牲 にして性能 を向上 | 大規模 データセット |
注意 :Cosine distance = 1 - Cosine similarity