Sorting
排序演算法詳細指南,包含視覺化動畫和應用場景分析。
Quicksort
快速排序 - 使用 Divide and Conquer 策略,選擇 pivot 進行分割排序
- Time Complexity
- Best:
- Average:
- Worst:
- Space Complexity:
- Stable: No
特點
- 平均情況下效能最佳
- In-place 排序
- 適合大型數據集
Mergesort
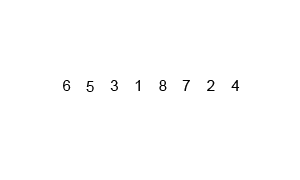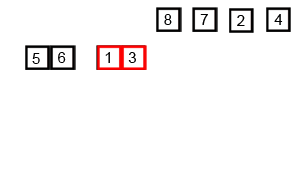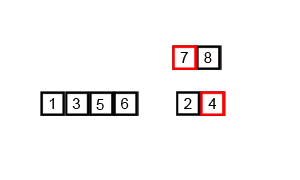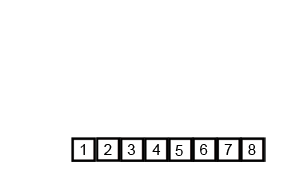
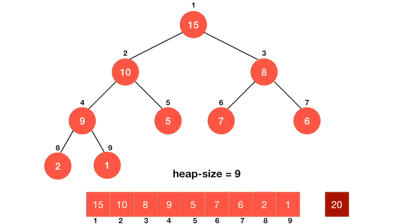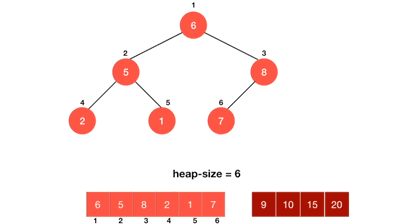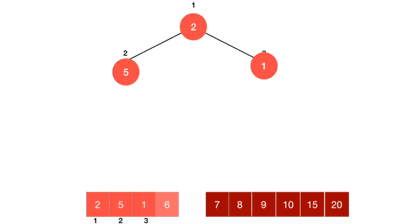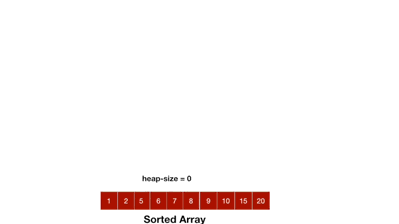
Heapsort
Bubble Sort
L to R
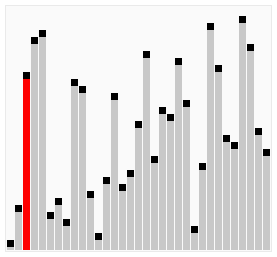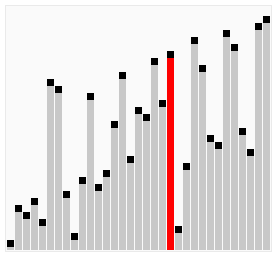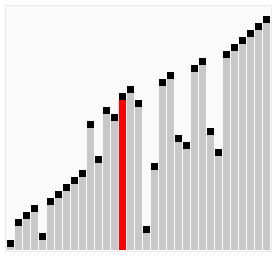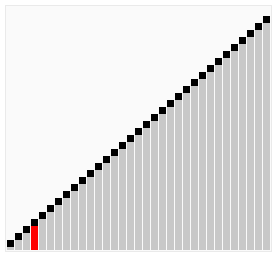
R to L

Selection Sort

Insertion Sort

使用場景和特性
a) Database
- 描述:在大型數據集中進行快速檢索和範圍查詢。
- 示例:客戶數據庫中按客戶ID排序,將查找時間從 O(n) 降低到 O(log n)。
- 適用算法:快速排序、合併排序
b) File System
- 描述:組織和顯示文件與目錄。
- 示例:按名稱、日期或大小排序文件,提高文件管理效率。
- 適用算法:快速排序、堆排序
c) 數值計算
- 描述:在科學計算和統計分析中進行數據預處理。
- 示例:計算數據集中位數時,先排序可顯著提高效率。
- 適用算法:合併排序、快速排序
d) 網絡流量管理
- 描述:優先級隊列管理和數據包調度。
- 示例:根據數據包優先級排序,確保高優先級流量(如實時視頻)優先處理。
- 適用算法:堆排序、計數排序(對於有限範圍的優先級)
e) 人工智能和機器學習
- 描述:特征選擇和模型優化。
- 示例:根據特征重要性排序,選擇最相關特征以提高模型性能。
- 適用算法:快速排序、合併排序
排序算法比較
| 排序算法 | 最佳使用情境 |
|---|---|
| 快速排序 (Quicksort) | 1. 大型數據集 2. 內存限制不嚴格 3. 平均情況性能要求高 4. 數據庫索引優化 |
| 合併排序 (Mergesort) | 1. 需要穩定排序 2. 外部排序 3. 鏈表排序 4. 並行計算環境 |
| 堆排序 (Heapsort) | 1. 內存受限 2. 需要保證最壞情況性能 3. 實時性要求高的系統 4. 優先隊列實現 |
| 冒泡排序 (Bubble Sort) | 1. 小型數據集 2. 教學用途 3. 幾乎已排序的數據 4. 簡單實現要求 |
| 插入排序 (Insertion Sort) | 1. 小型數據集 2. 幾乎已排序的數據 3. 在線算法(數據流) 4. 混合排序算法的一部分 |
| 選擇排序 (Selection Sort) | 1. 小型數據集 2. 內存受限 3. 教學用途 4. 最小化寫操作 |
| 計數排序 (Counting Sort) | 1. 整數排序 2. 範圍較小的數據 3. 重複元素多 4. 基數排序的子過程 |
| 基數排序 (Radix Sort) | 1. 整數或字符串排序 2. 數據位數較少 3. 並行處理 4. 大量數字或字符串的詞典排序 |
| Timsort | 1. 真實世界的數據,通常具有部分有序性質 2. Python 和 Java 的內置排序 3. 大型數據集 4. 需要穩定排序 |
| Tree Sort | 1. 需要維護一個排序的數據結構 2. 動態數據集,頻繁插入和刪除 3. 需要快速查找的場景 4. 數據集大小不確定 |
| Shell Sort | 1. 中等大小的數據集 2. 硬件層面有限的系統 3. 作為其他算法的預處理步驟 4. 需要原地排序算法 |
| Bucket Sort | 1. 均勻分布的數據 2. 浮點數排序 3. 外部排序 4. 並行計算環境 |
| Cubesort | 1. 大型數據集 2. 並行處理環境 3. 需要穩定排序 4. 適合硬件加速 |
這個合併後的表格提供了更全面的排序算法概覽,包括它們各自的最佳使用情境。這有助於在選擇排序算法時進行更全面的比較和權衡。
選擇合適排序算法的考慮因素
- 數據規模:大型數據集通常適合使用快速排序、合併排序或堆排序。
- 數據類型:整數、浮點數、字符串等不同類型可能適合不同的算法。
- 穩定性要求:如果需要保持相等元素的原始順序,選擇穩定的排序算法。
- 內存限制:在內存受限的情況下,考慮使用堆排序或原地排序算法。
- 預期的數據分佈:部分排序的數據可能更適合插入排序。
- 並行化需求:某些算法(如合併排序)更容易並行化。
- 實現複雜度:在時間緊迫或維護考慮下,可能優先選擇較簡單的算法。
後端開發中的排序演算法應用
1. 資料庫操作
- 在大多數情況下,資料庫本身會處理排序,但有時後端需要額外的排序操作。
a) 小型資料集排序(記憶體中排序)
- 場景:從資料庫取得少量記錄(如分頁查詢的單頁資料)後進行排序
- 推薦演算法:快速排序(QuickSort)或插入排序(Insertion Sort)
- 原因:快速排序平均效能好;插入排序對於小資料集或部分有序資料效率高
b) 大型資料集排序(外部排序)
- 場景:需要排序的資料量超過可用內存
- 推薦演算法:合併排序(Merge Sort)
- 原因:可以有效處理大型資料集,適合外部排序
2. API 回應資料處理
a) 即時資料排序
- 場景:API 需要傳回已排序的數據
- 推薦演算法:快速排序(QuickSort)或堆排序(HeapSort)
- 原因:這些演算法在平均情況下表現優秀,適合中型資料集
b) 部分排序(Top K 問題)
- 場景:只需要傳回排序後的前 K 個元素
- 推薦演算法:堆排序(HeapSort)或快速選擇演算法(QuickSelect)
- 原因:可以在不完全排序的情況下找出前 K 個元素
3. 日誌處理
a) 時間序列資料排序
- 場景:依照時間戳記對日誌進行排序
- 推薦演算法:TimSort(Java 和 Python 的預設排序演算法)
- 原因:對於部分有順序的資料(如時間戳記)表現優秀
b) 大規模日誌分析
- 場景:處理和分析大量歷史日誌數據
- 推薦演算法:外部合併排序(External Merge Sort)
- 原因:可以處理超出記憶體容量的大規模數據
4. 快取管理
a) LRU 緩存
- 場景:維護快取中元素的存取順序
- 推薦演算法:不需要完整排序,使用鍊錶+雜湊表的組合
- 原因:可在 O(1) 時間內進行插入、刪除和移動操作
5. 任務調度
a) 優先權佇列
- 場景:基於優先權的任務調度
- 推薦演算法:堆排序(HeapSort)或二元堆
- 原因:可以有效率地維護和更新優先權佇列
6. 文字處理
a) 字串排序
- 場景:對大量字串進行排序(如用戶名列表)
- 推薦演算法:基數排序(Radix Sort)或字典樹(Trie)
- 原因:對於固定長度或有限字元集的字串,這些演算法效率很高